Google Gemini: How AI Understands Video in Detail
Google Gemini's Artificial Intelligence can now 'see' and analyze videos with precision. Learn how this multimodal AI processes visuals and audio for deep understanding.
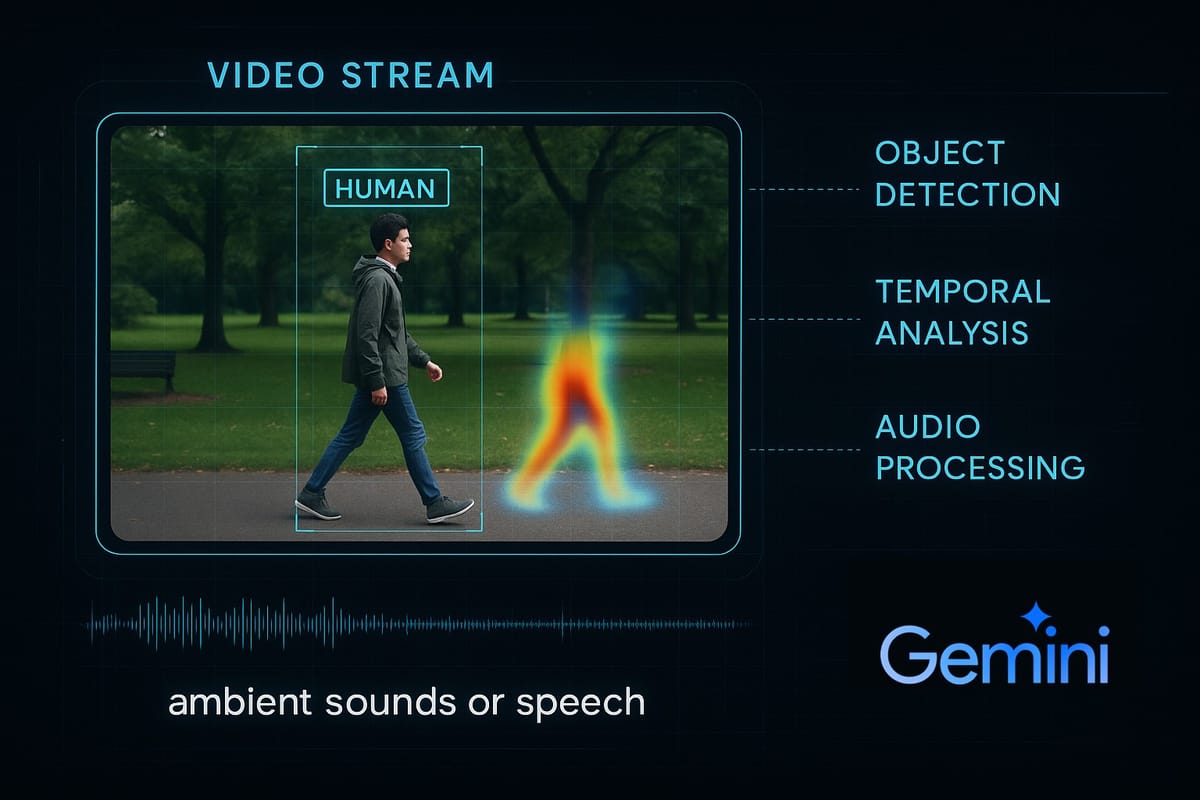
In this highly visual digital age, Artificial Intelligence's (AI) ability to understand and interpret video content has become a significant breakthrough. Advanced AI models, such as Google Gemini, now not only 'see' moving images but also analyze every visual and audio detail to build a comprehensive contextual understanding. This complex process involves a series of sophisticated stages that combine computer vision, natural language processing, and temporal analysis.
The Anatomy of Video for Artificial Intelligence
For AI, video is not just a single stream of data. Instead, video is decomposed into its fundamental components for effective processing. First, each video is broken down into a series of still images called frames. Each frame is then treated as an individual visual entity. Additionally, the audio track accompanying the video is extracted and processed separately. This separation is crucial as it allows AI to analyze both visual and audio modalities independently before integrating them for deeper comprehension.
Visual Processing: AI's Digital Eyes
The core of AI's ability to 'see' video lies in the field of Computer Vision. This technique enables AI to recognize and interpret visual elements within each frame.
Object and Scene Recognition
Each video frame is analyzed using Convolutional Neural Networks (CNNs). CNNs are a type of deep learningarchitecture highly effective at identifying spatial patterns. These models are trained with massive datasets to recognize various objects, from humans and vehicles to animals, and to identify scene types such as highways, beaches, or office interiors. As a result, AI can accurately detect the location of objects within a frame and classify them.
Segmentation and Pose Estimation
Furthermore, AI is also capable of performing segmentation, which involves separating specific objects from their backgrounds or dividing a frame into meaningful regions. For objects like humans, AI can even perform pose estimation, identifying the positions of joints and body parts, which is crucial for understanding movement and posture. This capability enables more advanced applications, such as motion analysis in sports or security monitoring.
Face and Emotion Recognition
If faces are present in the video, AI can identify individuals and even attempt to analyze their emotional expressions. This technology has been widely applied in various fields, from biometric authentication to audience sentiment analysis.
Temporal Understanding: The Time Dimension in Video Analysis
What distinguishes video understanding from static image understanding is the time dimension. AI must be able to track changes and relationships between frames over time.
Object Tracking and Activity Recognition
Once an object is detected in one frame, AI tracks its movement across the sequence of frames. This process is known as Object Tracking. By monitoring the movement and interaction of objects over time, AI can recognize ongoing activities or actions, such as running, jumping, or speaking. For these tasks, Recurrent Neural Networks (RNNs) like Long Short-Term Memory (LSTM, or more modern Transformer architectures, which are highly efficient at processing sequential data, are often used.
Event and Context Understanding
AI can also identify more complex events involving a series of activities, such as a sports match or a meeting. Beyond that, AI builds contextual understanding, grasping how these frames relate to each other to form a larger narrative or meaning from the entire video.
Audio Processing: Hearing What's Happening
The audio modality provides a crucial layer of information that complements visual data.
Automatic Speech Recognition (ASR)
If human speech is present in the video, AI uses Automatic Speech Recognition (ASR) to convert speech into text. This is essential for understanding dialogue, narration, or instructions conveyed in the video.
Non-Speech Sound Recognition
In addition to speech, AI can also identify non-speech sounds such as music, animal sounds, vehicle noises, or even laughter and screams. These sounds often provide rich additional context, helping AI understand the atmosphere or events taking place.
Multimodal Integration: The Power of Google Gemini in Video Understanding
Models like Google Gemini excel in Multimodal Integration, which is the ability to process and combine information from various modalities simultaneously.
Data Fusion and Richer Understanding
Visual information from frames, audio from sounds, and even text from subtitles or on-screen overlays are all combined and processed holistically by the model. By fusing these modalities, AI can achieve a much more accurate and nuanced understanding. For example, if Google Gemini sees someone running and hears screams, it can infer an emergency situation, which might not be clear from analyzing just one modality. This demonstrates how AI builds Cross-Modal Relationships for more comprehensive understanding.
AI Model Architecture and Training
Modern AI models used for video understanding are highly complex and based on Deep Learning. In addition to CNNs and RNNs/LSTMs, the Transformer architecture has become highly dominant due to its ability to handle long-range dependencies in sequential data and integrate various modalities through attention mechanisms. Some models even use 3D CNNs that process both spatial and temporal dimensions simultaneously.
Training these models requires Large-Scale Data that is meticulously labeled. The more extensive and diverse the data used, the better the understanding capabilities developed by the model. Self-Supervised Learning techniques also allow models to learn from unlabeled data, for instance, by predicting the next frame in a sequence or filling in missing parts of a video. For more information on deep learning, you can refer to our article on Fundamentals of Artificial Intelligence.
Real-World Applications of AI Video Understanding
AI's ability to understand video opens up a wide range of practical applications. Google Gemini, as a multimodal model, can perform tasks such as answering specific questions about video content ("What happened at 1:30?"), summarizing videos narratively, finding specific moments ("where did the cat jump?"), explaining complex activities, and transcribing and analyzing speech present in the video. This is highly useful in fields such as security surveillance, media content analysis, autonomous vehicles, and automated video summarization. Trusted sources like the Google AI Blog frequently publish the latest research on these advancements.
In essence, Google Gemini understands video by breaking it down into fundamental components, analyzing each part individually, and then integrating this information by comprehending how these elements change and interact over time. This process is powered by advanced deep learning architectures and training on vast video datasets. This capability continues to evolve, unlocking limitless potential for human interaction with technology in the future.


Comments ()